“大模型加速器2.0”上线,合合信息智能文档处理技术助力多行业“降幻增效”
近日,上海合合信息科技股份有限公司(简称“合合信息”)宣布其TextIn“大模型加速器2.0”版本正式上线,基于领先的智能文档处理技术,为行业带来了全新的解决方案。
“大模型加速器2.0”版本能够对复杂文档的版式、布局和元素进行精准解析及结构化处理,从数据源头降低大模型“幻觉”风险。升级后的“大模型加速器”在复杂版面理解、表格及图表处理、内容溯源等能力上实现了新突破。它可以精准识别上千种文档中的跨页表格、合并单元格、密集表格、手写字符及公式,解析稳定率高达99.99%,单页处理耗时较行业可比产品降低超30%。同时,该产品可“逆还原”十余种专业图表数据,并将其转化为大模型可理解的结构化数据。
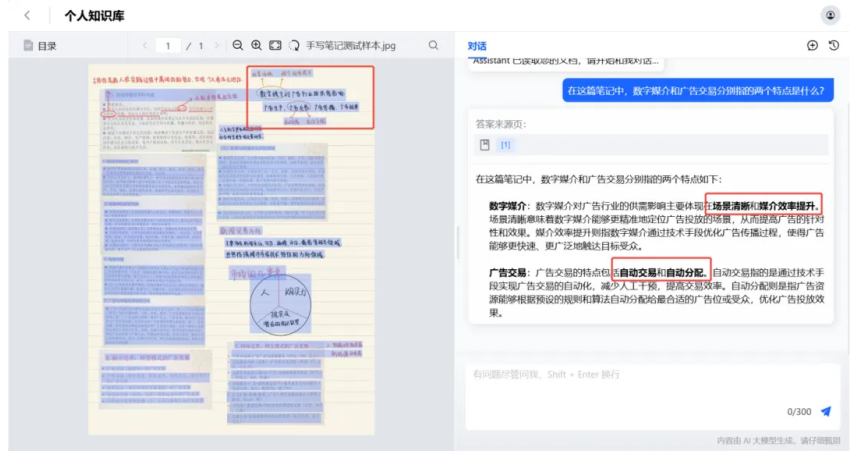
(“大模型加速器 2.0”文档解析引擎助力知识库理解手写笔记示意图)
在教育行业,文档格式多样且内容复杂,高效准确地提取各类文档中的文本信息并非易事。赛尔教育科技发展有限公司CTO、教育数字化事业部总经理杨林表示,教育行业大模型建设工作中,数据的数量和质量起着决定性作用,但模型的速度和准确性往往难以达到要求,严重影响科研工作的进展。合合信息文档解析技术为教育行业提供了专业的技术支持和服务,有效解决了文档处理过程中的难题。在“大模型加速器”的支持下,合合信息与赛尔教育共同协作,提升了大模型对复杂版面、元素的“理解力”,使其能够按照人类正常的阅读顺序识别文档结构,减少AI“幻觉”现象。
此外,“大模型加速器2.0”还新增了知识库系列开源组件,支持复杂文档的智能问答、总结与检索,并推出了溯源功能。通过在“投喂”给知识库的Markdown及JSON文件中标记页码、坐标等空间位置信息,该功能可实现对句子、段落的精确溯源,为用户提供了一个快速检验的路径。
目前,知识库组件已面向开发者开源,帮助其根据自身需要快速构建个性化行业知识库。合合信息表示,未来将持续优化迭代“大模型加速器”,助力大模型在各行各业中“百花齐放”,为更多行业提供高效、精准的文档处理解决方案。







